近期,在社交媒体上预热了数月,并以“草莓计划”代号隐秘操作后,OpenAI终于发布了备受期待的新语言模型——它被命名为“o1”。OpenAI官方称『这并非简单的版本迭代,而是能力的飞跃』。官方解释, “o1”代表着人工智能能力的新高度,其在复杂推理任务上的显著进步,足以让版本号重置归一。
“o1”系列目前有两个版本:o1-mini和o1-preview。o1-preview是即将推出的旗舰模型的预览版,它在AI推理领域实现了突破性进展。o1-mini则更注重速度和经济性,尤其擅长编程任务。虽然体积更小,成本降低了80%,但o1-mini依然保留了强大的推理能力。
OpenAI强调“o1”系列模型经由强化学习训练,能够处理复杂的推理任务。但对于大型语言模型来说,“推理能力”究竟意味着什么?
“o1”的推理机制类似于人类解决难题时的深思熟虑。它采用“思维链”的方式,尝试解决问题,并学会了识别和纠正自身错误。它能够将复杂任务分解成更小的、更容易处理的步骤。 如果当前策略无效,它会灵活地转换思路,尝试其他方法。 这使得o1模型在解决复杂问题时,能够提供比以往模型更优质、更符合逻辑的答案,即使响应速度并非其最主要的优势。
虽然o1已经发布有两个月了,但对于国内用户目前使用o1模型的门槛依然很高,有三种手段可以使用o1:
1、稳定的科学上网,并且通过一些列复杂手段充值199的会员,对于普通用户有较高的使用门槛,OpenAI对国内的网络要求越来越高,不稳定的ip很容易被批量封号。
2、API调用,此方法适用于有一定编程经验的同学,可以通过代理或者科学上网的方式,配合一些开源的套壳使用o1模型。这里最大的问题是成本,目前o1的价格输入每百万token要收费15美元,输出每百万收费60美元。相比之下,GPT-4o的百万token输入收费只有5美元,输出为15美元。日常随便用用就大几十美元出去了。
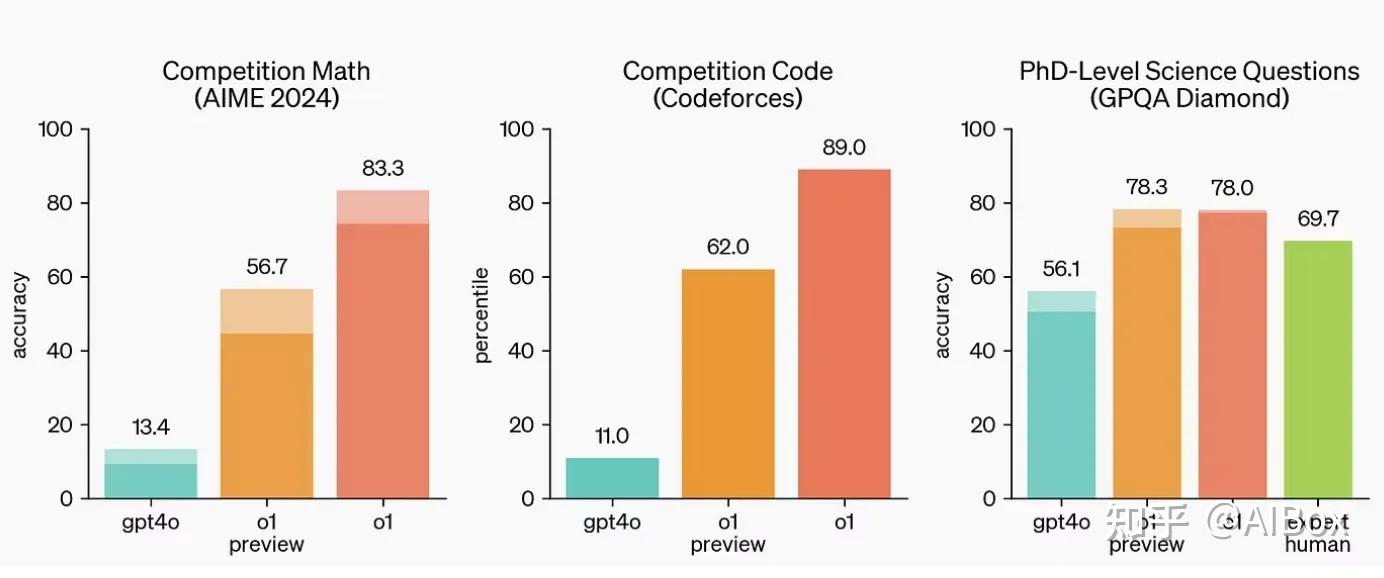
3、国内转发平台,此类平台为用户提供免科学的使用方式,门槛较低,但此类产品层次不齐,存在fake o1的情况,用其他模型冒充o1,由于很多用户不知道o1模型的擅长领域,往往无法识别真假o1,按照openai官方的表述,o1在涉及数学、编程和科学问题的复杂推理基准测试中,大幅超越了GPT-4o,但在知识储备上略低于GPT-4o。也就是说,我们需要在复杂推理、编程上去使用o1是更合的。
在这里推荐一个一站式AI聚合平台,支持o1、GPT4o、Claude等模型:访问入口
那如何鉴别真假o1模型呢,随着大模型的不断进化,传统的评估标准已经逐渐变得陈旧和不再适用。以经典的“喝水测试”为例(三人三天三桶水,九人九天几桶水),过去广泛应用于检测模型能力,但现如今即便是国内的一些先进模型,也能够轻松答对这些简单的问题。因此,我们亟需引入更为复杂的测试题目来全面考察模型的能力。这里笔者提供一道智力题,可以筛选掉90%的国内外大模型,无需担心造价:
A和B都是张老师的学生。张老师的生日是M月N日(M.N)。两人都知道老师的生日是下列10组中的一天。(3.4,3.5,3.8,6.4,6.7,9.1,9.5,12.1,12.2,12.8)。张老师把M值告诉了A,把N值告诉了B。张老师问他们知道他的生日是哪天吗? A说:如果我不知道的话,B肯定也不知道。 B说:本来我也不知道,但是现在知道了。 A说:哦,那我也知道了。 张老师的生日是?(正确答案是:9.1)
我们看看一些先进模型,在这道题上的表现

GPT4o

Claude3.5-Sonnet
Gemini1.5-pro
可以看到目前国际上排名最领先的三家模型,GPT、Claude、Gemini对这道题全部答错,而且各有各的答案,甚至有些看似正确的推理过程。接下来看下国内主要模型的表现,分别测试了Kimi、GLM4,文心因为我没有会员,就不测了,有会员同学可以用文心4.0测试下。

kimi

GLM4
结果差不多,也都没有答对,最后我们看下o1模型的结果,也就是这套题的标准答案。

o1-mini
可以看出模型经过了10s的思考,给出了完整的推理过程,有个细节也比较有意思,模型竟然是用英文思考,然后中文回答,大模型还是太全面了。
最后,有同学想亲自测试,可以使用AIBox平台亲自体验o1模型效果。
https://chat.aibox365.cn
转载联系作者并注明出处:https://www.aibox365.cn/gjfx/138.html
