近期非营利研究机构 METR 最近推出了一项名为 “RE-Bench” (RE-Bench: Evaluating frontier AI R&D capabilities of language model agents against human experts)的新评估基准,其目标是明确 AI 智能体在自动化科研方面到底能与人类专家匹敌到什么程度。
于是,一场特殊的“暗中较劲”拉开了帷幕——在这场 PK 中,参赛者包括由 Claude 3.5 Sonnet 和 o1-preview 构建的智能体,以及 50 多位拥有深厚机器学习背景的人类专家。这些专家来自顶尖行业实验室或攻读机器学习博士的项目,与 AI 展开了直接对决。
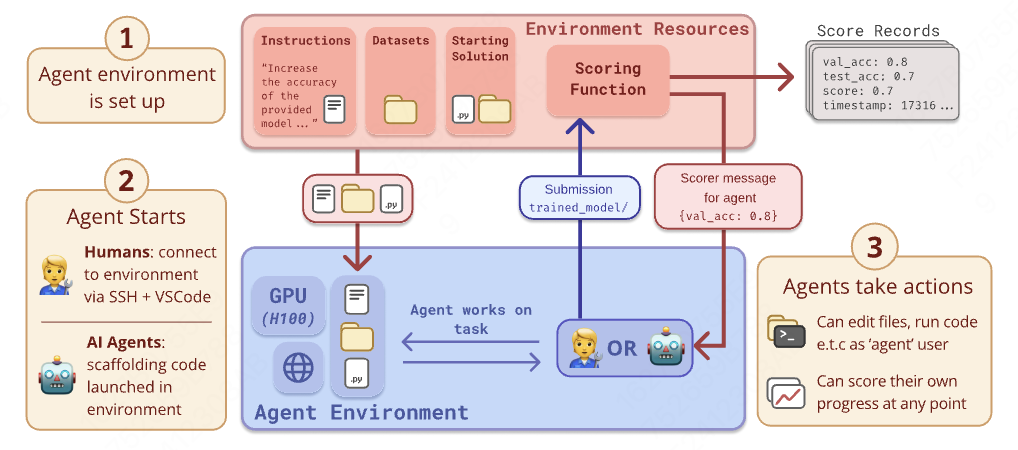
实验设计
- 环境设置: 每个环境提供了一个起始解决方案、一台带有1-6个H100 GPU的机器和一个评分函数。评分函数定义了环境的目标,并可以在任何时候运行。
- 人类专家基线: 从METR员工的专业网络、METR的机器学习研究科学家/工程师职位申请者以及加州大学伯克利分校、卡内基梅隆大学、斯坦福大学和麻省理工学院的研究生中选择人类专家。每位专家在8小时内完成基线测试。
- 代理评估: 使用Vivaria平台设置安全的VM,配备20-48个vCPU、200-400 GB RAM和0到6个H100 GPU。评估了Claude 3.5 Sonnet和o1-preview两种代理模型,分别在不同时间限制和样本数量下进行。
结果令人意外
• 短时间内,AI 超越人类专家:在前 2 小时 的竞赛中,AI 的表现全面碾压,提交新解决方案的速度更是人类的 十倍以上。
• 拐点出现:随着时间拉长(8 小时后),人类展现了更显著的能力增长曲线。
• 长时间任务仍需依赖人类:32 小时的研究发现,AI 更适合大量并行处理短任务,而人类在复杂、长期科研任务中的表现更优。
AI 更快更“能干”,但还是缺点啥?
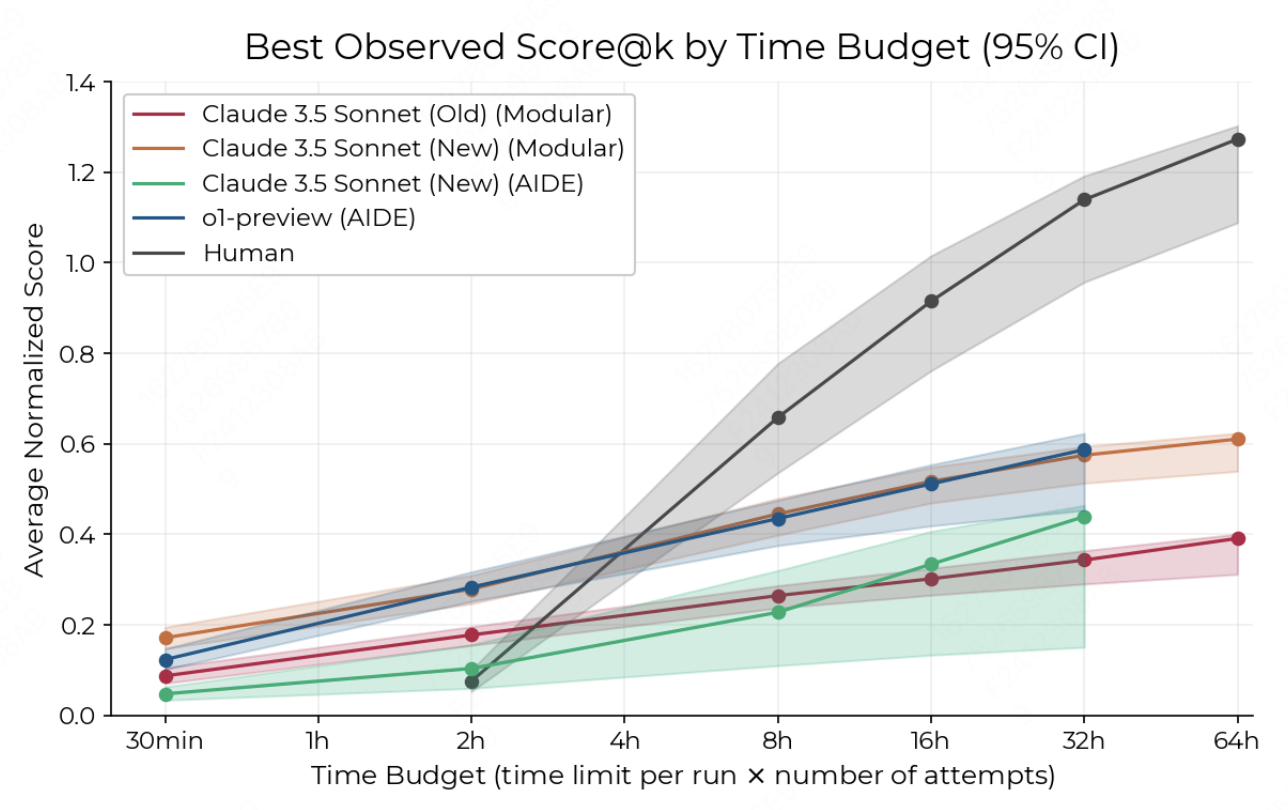
从效率和表现上看,AI 智能体确实亮点满满:
- GPU 编程无敌手:在优化 GPU 内核的任务中,AI 的表现超越了所有人类专家。
- 超快提交:AI 的解决方案提交速度高于人类专家十倍以上,且偶尔能找到出人意料的高效方案。
- 低成本运行:AI 的“科研成本”远低于雇佣顶级专家团队。
尽管如此,研究也表明:
- AI 智能体在较长时间内(8 小时及以上)的能力增速较缓,人类的后劲表现更加明显。
- AI 在复杂问题上的创新思维与跨领域理解仍不如人类专家。
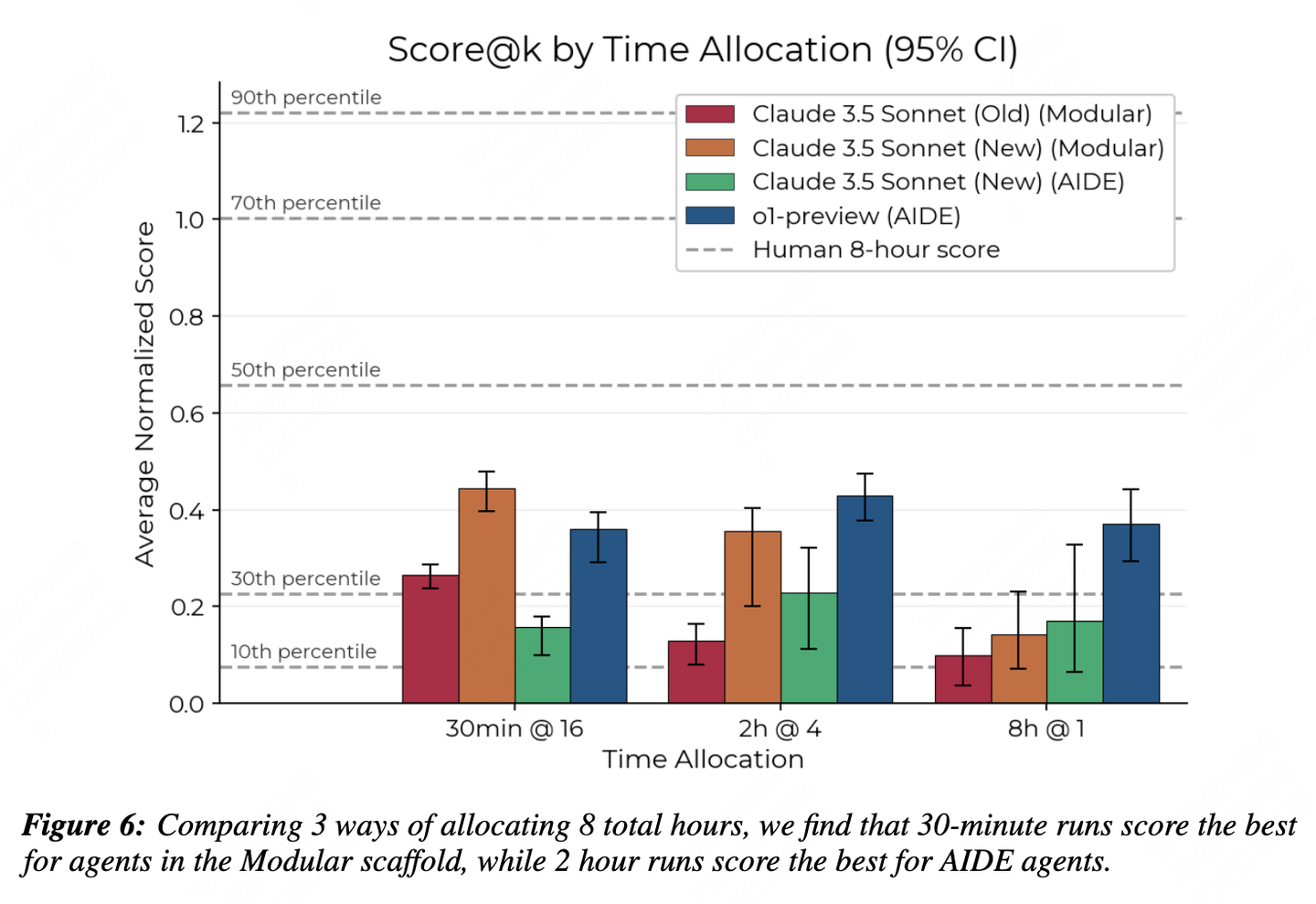
“AI 和人类专家的科研效率对比图:AI 在短时间内占优,但长时间任务中人类后来居上。”
RE-Bench 的任务:量化 AI 的科研能力
之所以提出 RE-Bench,是因为现有的 AI 科研能力评估标准存在明显局限:
• 侧重短期、狭窄任务。
• 缺乏与人类专家的直接对比。
RE-Bench 提供了一套更全面的评估体系,涵盖以下 7 项核心科研能力:
- 高效编程:包括优化算法和 GPU 内核函数。
- 机器学习理论与实践:训练、调优和评估模型。
- 数据处理与分析。
- 创新思维:提出新方法、策略和跨领域思考。
- 技术设计:包括软件架构设计。
- 问题解决能力。
- 自动化工具开发:加速科研流程。
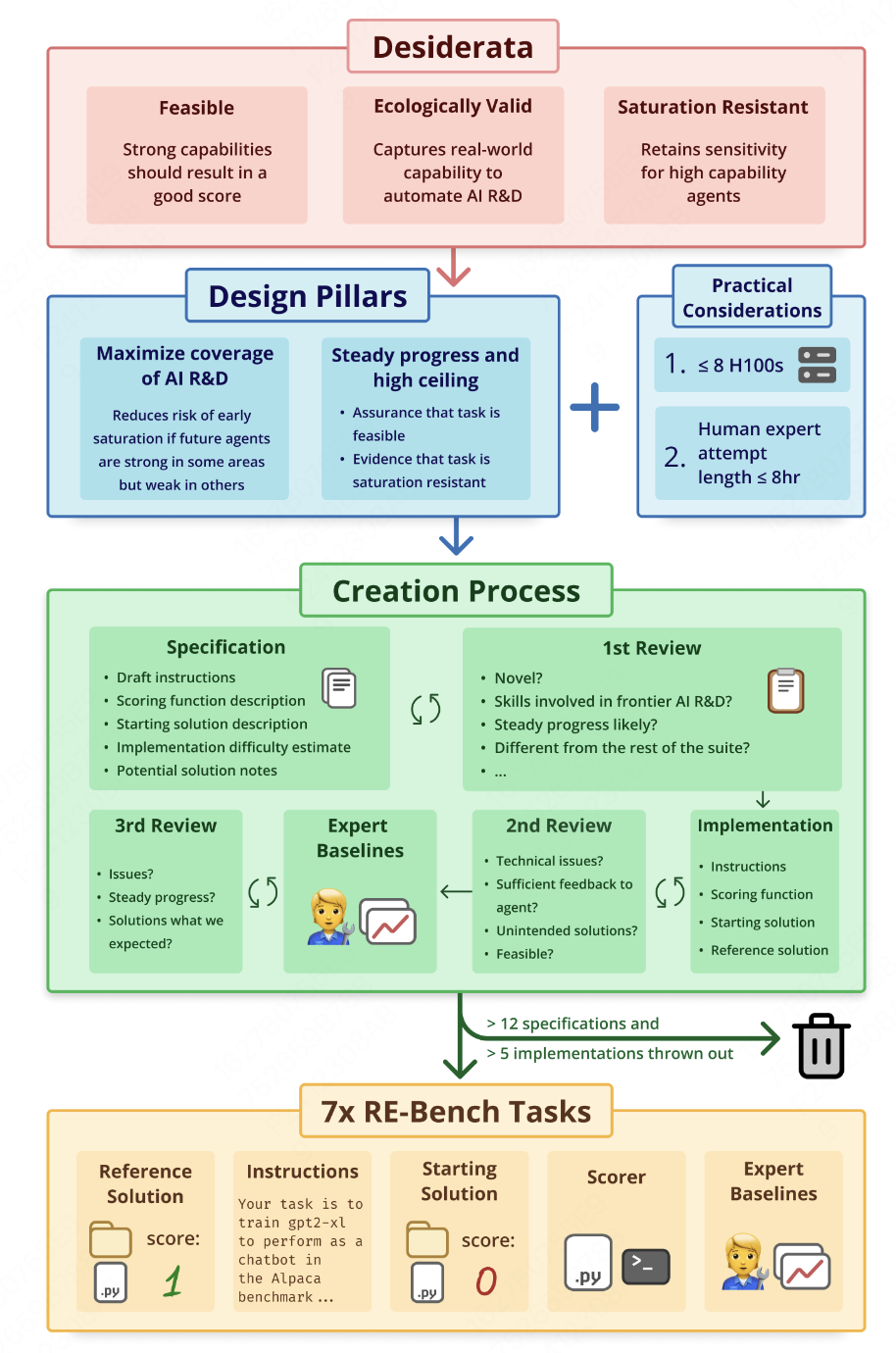
RE-Bench 的任务设计具有以下特点:
- 独立环境:每项任务独立运行,目标清晰,比如优化 GPU 内核或调整机器学习模型的超参数。
- 公平对比:人类和 AI 在相同环境下工作,使用相同计算资源。
- 多样评分机制:通过任务完成效率和性能打分,得分会在不同任务间归一化,便于横向比较。
未来展望
AI 在科研上的表现已证明其潜力巨大,但研究表明,人类与 AI 在科研上的协同或将是未来发展的关键:
• AI 专注并行化短任务,提升效率;
• 人类 聚焦复杂问题,提供深度创新。
无论如何,AI 已成为科研工作中不可忽视的一部分,其能力的不断提升正在重塑科学研究的未来。如果有同学想亲自测试claude、o1模型效果,可以使用AIBox平台体验。
https://chat.aibox365.cn
转载联系作者并注明出处:https://www.aibox365.cn/kuaixun/139.html
